

Matrices and properties
Importance of linear equations
First mathematical models of many of the real world problems are either linear or can be
approximated reasonably well using linear relationships. Analysis of linear relationship of variables
is generally easier than that of non-linear relationships.
A linear equation involving two variables x and y has the standard form 𝑎𝑥 + 𝑏𝑦 = 𝑐, where a, b&
c are real numbers and a and b both cannot be equal to zero.
The equation becomes non-linear if any of the variables has the exponent other than one, example
4𝑥 + 5𝑦 = 15 𝑙𝑖𝑛𝑒𝑎𝑟
4𝑥 − 𝑥𝑦 + 5𝑦 = 15𝑛𝑜𝑛 – 𝑙𝑖𝑛𝑒𝑎𝑟
𝑥 2 + 5𝑦 2 = 15 𝑛𝑜𝑛 − 𝑙𝑖𝑛𝑒𝑎r
Linear equation occurs in more than two variables as 𝑎1𝑥1 + 𝑎2𝑥2 + 𝑎3𝑥3 + ⋯ 𝑎𝑛𝑥𝑛 = 𝑏. The set of equations is known as system of simultaneous equations, in matrix form it can be represented as
𝐴𝑥 = 𝐵
3𝑥1 + 2𝑥2 + 4𝑥3 = 14
𝑥1 − 2𝑥2 = −7
−𝑥1 + 3𝑥2 + 2𝑥3 = 2
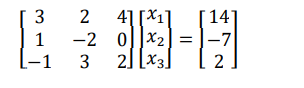
Existence of solution
In solving system of equations we find values of variables that satisfy all equations in the system
simultaneously. There may be 4 possibility in solving the equations.
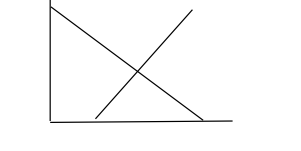
- System with unique solution
here the lines or equations intersect in one and only one point.
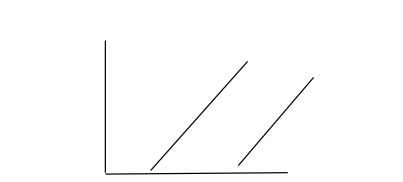
2. System with no solution
Here the lines or equation never intersect or parallel lines.
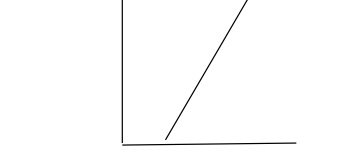
3. System with infinite solution
Here two equation or lines overlap, so that there is infinite
Solutions
4. ILL condition system
There may be situation where the system has a solution but it is very close to being
singular, i.e, any equation have solution but is very difficult to identify the exact point at
which the lines intersect. If there is any slight changes in the value in the equation then we
will see huge change in the solution, this type of equation is called ILL condition system,
we should be careful in solving these kind of solutions. Example

1.01𝑥 + 0.99𝑦 = 2
0.99𝑥 + 1.01𝑦 = 2
On solving these equations we get the solution at x=1 & y=1, however if we make small
changes in b i.e.
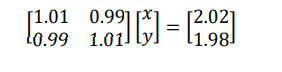
1.01𝑥 + 0.99𝑦 = 2.02
0.99𝑥 + 1.01𝑦 = 1.98
On solving these equation we get x=2 & y=0
So slight changes results in huge change in solution.
Methods of solutions
Elimination method
Elimination method is a method of solving simultaneous linear. This method involves elimination
of a term containing one of the unknowns in all but one equation, one such step reduces the order
of equations by one, repeated elimination leads finally to one equation with one unknown.
Example: solve the following equation using elimination method
4𝑥1 − 2𝑥2 + 𝑥3 = 15 … … (1)
−3𝑥1 − 𝑥2+4𝑥3 = 8 … … (2)
𝑥1 − 𝑥2 + 3𝑥3 = 13 … … (3)
Here multiply 𝑅1 𝑏𝑦 3 &𝑅2 𝑏𝑦 4 and add to eliminate 𝑥1from 2. Multiply 𝑅1 𝑏𝑦 − 1&𝑅3 𝑏𝑦 4 and add to eliminate 𝑥1from 3
4𝑥1 − 2𝑥2 + 𝑥3 = 15
−10𝑥2+19𝑥3 = 77
−2𝑥2 + 11𝑥3 = 37
Now to eliminate 𝑥2 from third equation multiply second row by 2 and third row by -10 and adding
4𝑥1 − 2𝑥2 + 𝑥3 = 15
−10𝑥2+19𝑥3 = 77
−72𝑥3 = −216
Now we have a triangular system and solution is readily obtained from back-substitution
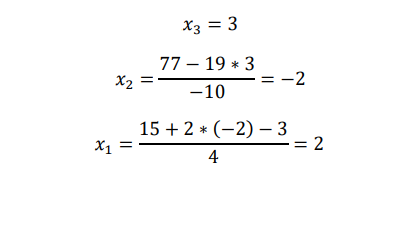
Gauss Elimination Method
The procedure in above example may not be satisfactory for large systems because the transformed coefficients can become very large as we convert to a triangular system. So we use another method called Gaussian Elimination method that avoid this by subtracting 𝑎𝑖1/ 𝑎11 times the first equation from 𝑖 𝑡ℎ equation to make the transformed numbers in the first column equal to zero and proceed on. However we must always guard against divide by zero, a useful strategy to avoid divide by zero is to re-arrange the equations so as to put the coefficient of large magnitude on the diagonal at each step, this is called pivoting. Complete pivoting method require both row and column interchange but this is much difficult and not frequently done. Changing only row called partial pivoting which places a coefficient of larger magnitude on the diagonal by row interchange only. This will be guaranteeing a non-zero divisors if there is a solution to set of equations and will have the added advantage of giving improved arithmetic precision. The diagonal elements that result are called pivot elements.
Example (without pivoting element)
0.143𝑥1 + 0.357𝑥2 + 2.01𝑥3 = −5.173
−1.31𝑥1 + 0.911𝑥2 + 1.99𝑥3 = −5.458
11.2𝑥1 − 4.30𝑥2 − 0.605𝑥3 = 4.415
Augmented matrix is
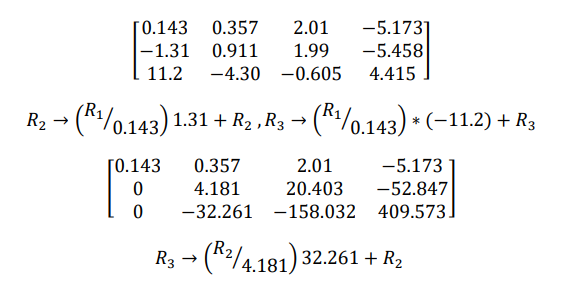



Gauss Jordan Method
Gauss Jordan method is another popular method used for solving a system of linear equations. In
this method the elements above the diagonal are made zero at the same time that zero are
created below the diagonal, usually the diagonal elements are made ones at the same time the
reduction is performed, this transforms the coefficient matrix into identity matrix. When this has
been accomplished the column of right-hand side has been transformed into the solution vector.
Pivoting is normally employed to preserve arithmetic accuracy.
Example solution using Gauss-Jordan method
2𝑥1 + 4𝑥2 − 6𝑥3 = −8
𝑥1 + 3𝑥2 + 𝑥3 = 10
2𝑥1 − 4𝑥2 − 2𝑥3 = −12

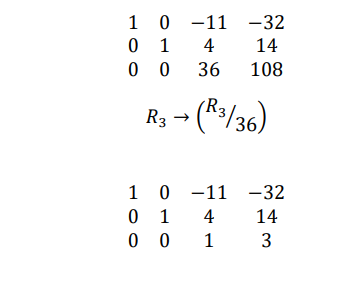

Example solution using Gauss-Jordan method (with pivoting)
2𝑥1 + 4𝑥2 − 6𝑥3 = −8
𝑥1 + 3𝑥2 + 𝑥3 = 10
2𝑥1 − 4𝑥2 − 2𝑥3 = −12
Augmented matrix is


The inverse of a matrix
The division a matrix is not defined but the equivalent is obtained from the inverse of the matrix. If the product of two square matrices A*B equals identity matrix I, B is said to be inverse of A (also A is inverse of B). the usual notation of the matrix is 𝐴 −1 . we can say as 𝐴𝐵 = 𝐼, 𝐴 = 𝐵 −1 ,𝐵 = 𝐴 −1 .
Example: given matrix A, find the inverse of A using Gauss Jordan method.
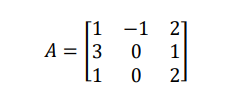

Method of factorization
Consider the following system of equations
𝑎11𝑥1 + 𝑎12𝑥2 + 𝑎13𝑥3 = 𝑏1
𝑎21𝑥1 + 𝑎22𝑥2 + 𝑎23𝑥3 = 𝑏2
𝑎31𝑥1 + 𝑎32𝑥2 + 𝑎33𝑥3 = 𝑏3
These equations can be written in matrix form as
𝐴𝑋 = B

n this method we use the fact that the square matrix A can be factorized into the form LU, where
L is lower triangular matrix and U can be upper triangular matrix such that 𝐴 = 𝐿𝑈
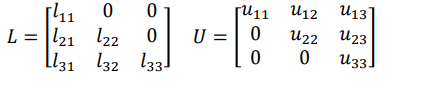
𝐿𝑈𝑋 = 𝐵
Let us assume 𝑈𝑋 = 𝑍 , then 𝐿𝑍 = 𝐵
Now we can solve the system A𝑋 = 𝐵 in two stages
- Solve the equation, 𝐿𝑍 = 𝐵 for Z by forward substitution
- Solve the equation, 𝑈𝑋 = 𝑍 for X using Z by backward substitution.
The elements of L and u can be determined by comparing the elements of the product of L and U
with those of A. The decomposition with L having unit diagonal values is called the Dolittle LU
decomposition while the other one with U having unit diagonal elements is called Crout LU
decomposition.
Dolittle LU decomposition
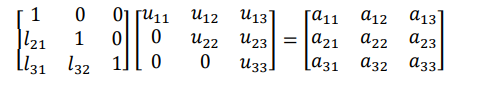

Equating the corresponding coefficients we get the values of l and u
Example: Now find L & U either by using Dolittle algorithm
2𝑥 − 3𝑦 + 10𝑧 = 3
−𝑥 + 4𝑦 + 2𝑧 = 20
5𝑥 + 2𝑦 + 𝑧 = −12
The given system is 𝐴𝑥 = 𝐵, where

Now comparing both sides we get
𝑢11 = 2
𝑢12 = −3
𝑢13 = 10
𝑙21𝑢11 = −1
𝑙21 = − 1/ 2
𝑙21𝑢12 + 𝑢22 = 4
𝑢22 = 5/ 2
𝑙21𝑢13 + 𝑢23 = 2
𝑢23 = 7
𝑙31𝑢11 = 5
𝑙31 = 5/ 2
𝑙31𝑢12 + 𝑙32𝑢22 = 2
𝑙32 = 19 /5
𝑙31𝑢13 + 𝑙32𝑢23 + 𝑢33 = 1
𝑢33 = − 253/ 5

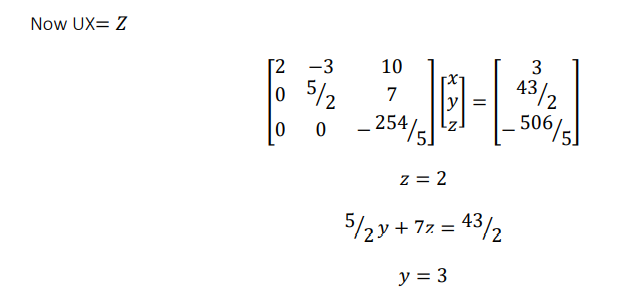
2𝑥 − 3𝑦 + 10𝑧 = 3
𝑥 = −4
Crout’s method
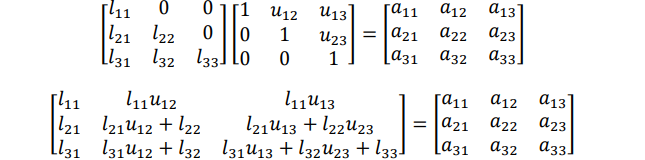
Equating the corresponding coefficients, we get the values of l and u
Example solve the following system by the method of crouts algorithms factorization
2𝑥 − 3𝑦 + 10𝑧 = 3
−𝑥 + 4𝑦 + 2𝑧 = 20
5𝑥 + 2𝑦 + 𝑧 = −12
The given system is 𝐴𝑥 = 𝐵, where
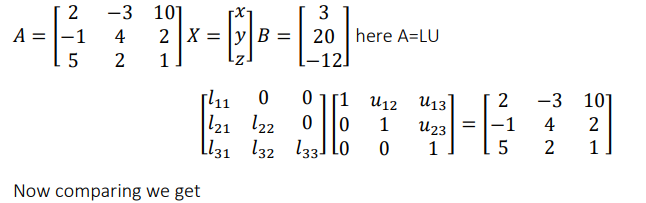
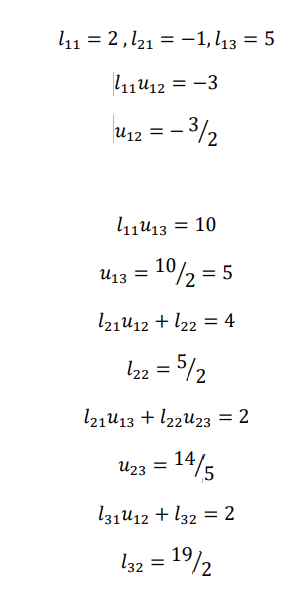
𝑙31𝑢13 + 𝑙32𝑢23 + 𝑙33 = 1
𝑙33 = − 253/ 5
So we have
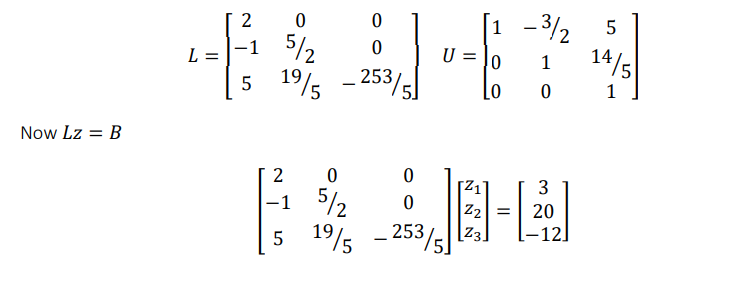
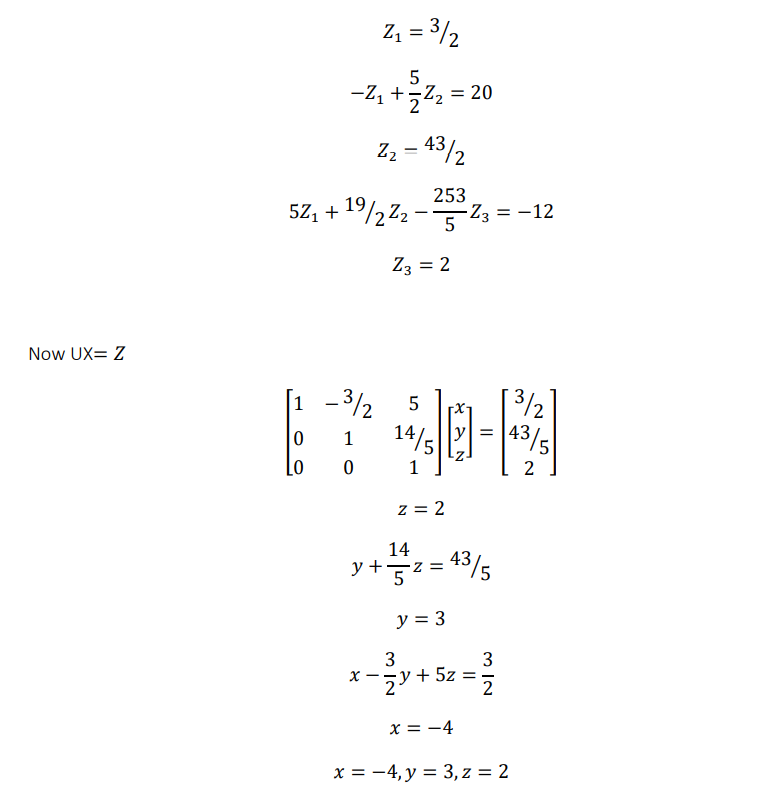
Choleskys method
In case of A is symmetric, the LU decomposition can be modified so that upper factor in matrix is
the transpose of the lower one (vice versa)
i.e. 𝐴 = 𝐿𝐿 𝑇 = 𝑈 𝑇 𝑈
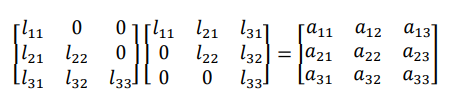
Just as other method, perform as before
Symmetric matrix
A square matrix 𝑨 = [𝒂𝒊𝒋] is called symmetric if 𝒂𝒊𝒋= 𝒂𝒋𝒊 for all i and j
Example: factorize the matrix, using Cholesky algorithm

Iterative methods
Gauss elimination and its derivatives are called direct method, an entirely different way to solve
many systems is through iteration. In this we start with an initial estimate of the solution vector
and proceed to refine this estimate.
When the system of equation can be ordered so that each diagonal entry of the coefficient matrix
is larger in magnitude that the sum of the magnitude of the other coefficients in that row, then
such system is called diagonally dominant and the iteration will converge for any stating values.
Formally we say that an nxn matrix A is diagonally dominant if and only if for each i=1, 2, 3….n
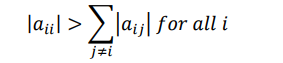
The iterative method depends on the arrangement of the equations in this manner
Let us consider a system of n equations in n unknowns
𝑎11𝑥1 + 𝑎12𝑥2 + ⋯ + 𝑎1𝑛𝑥𝑛 = 𝑏1
𝑎21𝑥1 + 𝑎22𝑥2 + ⋯ + 𝑎2𝑛𝑥𝑛 = 𝑏2
𝑎𝑛1𝑥1 + 𝑎𝑛2𝑥2 + ⋯ + 𝑎𝑛𝑛𝑥𝑛= 𝑏𝑛
We write the original system as

Now we can computer 𝑥1, 𝑥2 … 𝑥𝑛by using initial guess for these values. The new values area gain used to compute the next set of x values. The process can continue till we obtain a desired level of accuracy in x values.
Example
Solve the equation using Gauss Jacobi iteration method
6𝑥1 − 2𝑥2 + 𝑥3 = 11
𝑥1 + 2𝑥2 − 5𝑥3 = −1
−2𝑥1 + 7𝑥2 + 2𝑥3 = 5
Now first we recorder the equation so that coefficient matrix is diagonally dominant
6𝑥1 − 2𝑥2 + 𝑥3 = 11
−2𝑥1 + 7𝑥2 + 2𝑥3 = 5
𝑥1 + 2𝑥2 − 5𝑥3 = −1
Now

We can simplify as
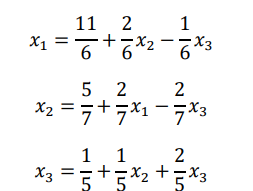
We begin with some initial approximation to the value of the variables,
let’s take as 𝑥1 = 0, 𝑥2 = 0, 𝑥3 = 0,
Then new approximation using above formula will be as follows
| 1 Iteration |
| 𝑥1=1.833333 |
| 𝑥2=0.714286 |
| 𝑥3=0.200000 |
| 2 Iteration |
| 𝑥1=2.038095 |
| 𝑥2 =1.180952 |
| 𝑥3=0.852381 |
| 3 Iteration |
| 𝑥1=2.084921 |
| 𝑥2=1.053061 |
| 𝑥3=1.080000 |
| 4 Iteration |
| 𝑥1=2.004354 |
| 𝑥2=1.001406 |
| 𝑥3=1.038209 |
| 5 Iteration |
| 𝑥1=1.994100 |
| 𝑥2=0.990327 |
| 𝑥3=1.001433 |
| 6 Iteration |
| 𝑥1=1.996537 |
| 𝑥2=0.997905 |
| 𝑥3=0.994951 |
| 7 Iteration |
| 𝑥1=2.000143 |
| 𝑥2=1.000453 |
| 𝑥3=0.998469 |
| 8 Iteration |
| 𝑥1=2.000406 |
| 𝑥2=1.000478 |
| 𝑥3=1.000210 |
| 9 Iteration |
| 𝑥1=2.000124 |
| 𝑥2=1.000056 |
| 𝑥3=1.000273 |
| 10 Iteration |
| 𝑥1=1.999973 |
| 𝑥2=0.999958 |
| 𝑥3=1.000047 |
| 11 Iteration |
| 𝑥1=1.999978 |
| 𝑥2=0.999979 |
| 𝑥3=0.999978 |
| 12 Iteration |
| 𝑥1=1.999997 |
| 𝑥2=1.000000 |
| 𝑥3=0.999987 |
| 12 Iteration the final result is : |
| 𝑥1=1.999997 𝑥2=1.000000 𝑥3=0.999987 |
Gauss Seidel Iteration method
This is a modification of Gauss Jacobi method, as before
Let us consider a system of n equations in n unknowns
𝑎11𝑥1 + 𝑎12𝑥2 + ⋯ + 𝑎1𝑛𝑥𝑛 = 𝑏1
𝑎21𝑥1 + 𝑎22𝑥2 + ⋯ + 𝑎2𝑛𝑥𝑛 = 𝑏2
𝑎𝑛1𝑥1 + 𝑎𝑛2𝑥2 + ⋯ + 𝑎𝑛𝑛𝑥𝑛 = 𝑏3
We write the original system as

Now we can computer 𝑥1, 𝑥2 … 𝑥𝑛 by using initial guess for these values. Here we use the updated values of 𝑥1, 𝑥2 … 𝑥𝑛 in calculating new values of x in each iteration till we obtain a desired level of accuracy in x values. This method is more rapid in convergence than gauss Jacobi method. The rate of convergence of gauss seidel method is roughly twice that of gauss Jacobi.
Example
Solve the equation using Gauss Seidel iteration method
8𝑥1 − 3𝑥2 + 2𝑥3 = 20
6𝑥1 + 3𝑥2 + 12𝑥3 = 35
4𝑥1 + 11𝑥2 − 𝑥3 = 33
Now first we recorder the equation so that coefficient matrix is diagonally dominant
8𝑥1 − 3𝑥2 + 2𝑥3 = 20
4𝑥1 + 11𝑥2 − 𝑥3 = 33
6𝑥1 + 3𝑥2 + 12𝑥3 = 35
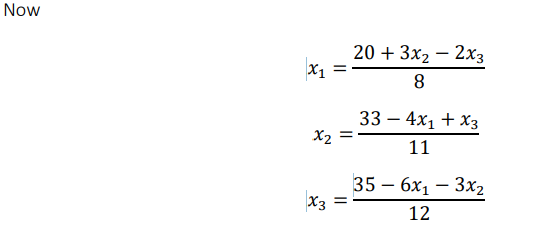
We begin with some initial approximation to the value of the variables,
let’s take as 𝑥2 = 0, 𝑥3 = 0,
Then new approximation using above formula will be as follows
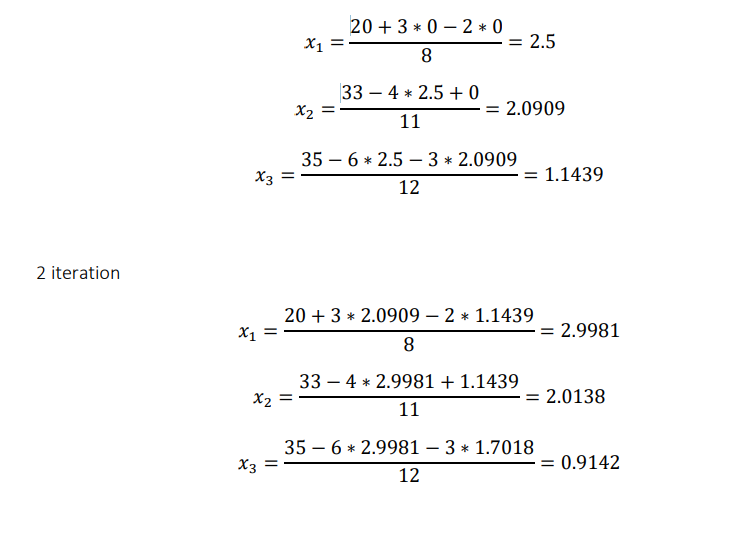


Since the 6th and 7th approximate are almost same up to 4 decimal places, we can the result is
𝑥1 = 3.0168, 𝑥2 = 1.9859, 𝑥3 = 0.9118
Power method
Power method is a single value method used for determining the dominant eigen value of a matrix.
It as an iterative method implemented using an initial starting vector x. the starting vector can be
arbitrary if no suitable approximation is available. Power method is implemented as follows
𝑌 = 𝐴𝑋 − − − − − (𝑎)
𝑋 = 𝑌/𝑘 − − − − − (𝑏)
The new value of X is obtained in b is the used in equation a to compute new value of Y and the
process is repeated until the desired level of accuracy is obtained. The parameter k is called scaling
factor is the element of Y with largest magnitude.
Example: find the largest Eigen value 𝜆 and the corresponding vector v, of the matrix using power
method


Reference 1 : Numerical Methods , Dr. V.N. Vedamurthy & Dr. N. Ch. S. N. Iyengar, Vikas Publishing House.